How To Make An Imaginary Friend
Posted: December 13, 2015 Filed under: Anna Brown Massey, Final Project 1 Comment »An audience of six walk into a room. They crowd the door. Observing their attachment to remaining where they’ve arrived, I am concerned the lights are set too dark, indicating they should remain where they are, safe by a wall, when my project will soon require the audience to station themselves within the Kinect sensor zone at the room’s center. I lift the lights in the space, both on them and into the Motion Lab. Alex introduces the concepts behind the course, and welcomes me to introduce myself and my project.
In this prototype, I am interested in extracting my live self from the system so that I may see what interaction develops without verbal directives. I say as much, which means I say little, but worried they are still stuck by the entrance (that happens to host a table of donuts), I say something to the effect of “Come into the space. Get into the living room, and escape the party you think is happening by the kitchen.” Alex says a few more words about self-running systems–perhaps he is concerned I have left them too undirected–and I return to station myself behind the console. Our six audience members, now transformed into participants, walk into the space.

Participants approach the Action Zone.
I designed How to make an imaginary friend as a schema to compel audience members, now rendered participants, to respond interactively through touching each other. Having achieved a learned response to the system and gathered themselves in a large single group because of the cumulative audio and visual rewards, the system would independently switch over to a live video feed as output, and their own audio dynamics as input, inspiring them to experiment with dynamic sound.
System as Descriptive Flow Chart
Front projection and Kinect are on, microphone and video camera are set on a podium, and Anna triggers Isadora to start scene.
> Audience enters MOLA
“Enter the action zone” is projected on the upstage giant scrim
> Intrigued and reading a command, they walk through the space until “Enter the action zone” disappears, indicating they have entered.
Further indication of being where there is opportunity for an event is the appearance of each individual’s outline of their body projected on the blank scrim. Within the contours of their projected self appears that slice of a movie, unmasked within their body’s appearance on the scrim when they are standing within the action zone.
> Inspired to see more of the movie, they realize that if they touch or overlap their bodies in space, they will be able to see more of the movie.

In attempts at overlapping, they touch, and Isadora reads a defined bigger blob, and sets off a sound.
> Intrigued by this sound trigger, more people overlap or touch simultaneously, triggering more sounds.
> They sense that as the group grows, different sounds will come out, and they continue to connect more.
Reaching the greatest size possible, the screen is suddenly triggered away from the projected appearance, and instead projects a live video feed.
They exclaim audibly, and notice that the live feed video projection changes.
> The louder they are, the more it zooms into a projection of themselves.
They come to a natural ending of seeing the next point of attention, and I respond to any questions.
Analysis of Prototype Experiment 12/11/15
As I worked over the last number of weeks I recognized that shaping an experiential media system renders the designer a Director of Audience. I newly acknowledged once the participants were in the MOLA and responding to my design, I had become a Catalyzer of Decisions. And I had a social agenda.
There is something about the simple phrase “I want people to touch each other nicely” that seems correct, but also sounds reductive–and creepily problematic. I sought to trigger people to move and even touch strangers without verbal or text direction. My system worked in this capacity. I achieved my main goal, but the cumulative triggers and experiences were limited by an all-MOLA sound system failure after the first few minutes. The triggered output of sound-as-reward-for-touch worked only for the first few minutes, and then the participants were left with a what-next sensibility sans sound. Without a working sound system, the only feedback was the further discovery of unmasking chunks of the film.

Participant experiments with body placement to determine triggers.
Because of the absence of the availability of my further triggers, I got up and joined them. We talked as we moved, and that itself interested me–they wanted to continue to experiment with their avatars on screen despite a lack of audio trigger and an likely a growing sense that they may have run out of triggers. Should the masked movie been more engaging (this one was of a looped train rounding a station), they might have been further engaged even without the audio triggers. In developing this work, I had considered designing a system in which there was no audio output, but instead the movement of the participants would trigger changes in the film–to fast forward, stop, alter the image. This might be a later project, and would be based in the Kinect patch and dimension data. Further questions arise: What does a human body do in response to their projected self? What is the poetic nature of space? How does the nature of looking at a screen affect the experience and action of touch?
Plans for Following Iteration
- “Action zone” text: need to dial down sensitivity so that it appears only when all objects are outside of the Kinect sensor area.
- Not have the sound system for the MOLA fail, or if this happens again, pause the action, set up a stopgap of a set of portable speakers to attach to the laptop running Isadora.
- Have a group of people with which to experiment to more closely set the dimensions of the “objects” so that the data of their touch sets off a more precisely linked sound.
- Imagine a different movie and related sound score.
- Consider an opening/continuous soundtrack “background” as scene-setting material.
- Consider the integrative relationship between the two “scenes”: create a satisfying narrative relating the projected film/touch experience to the shift to the audio input into projected screen.
- Relocate the podium with microphone and videocamera to the center front of the action zone.
- Examine why the larger dimension of the group did not trigger the trigger of the user actor to switch to the microphone input and live video feed output.
- Consider: what was the impetus relationship between the audio output and the projected images? Did participants touch and overlap out of desire to see their bodies unmask the film, or were they relating to the sound trigger that followed their movement? Should these two triggers be isolated, or integrated in a greater narrative?
Video available here: https://vimeo.com/abmassey/imaginaryfriend
Password: imaginary
All photos above by Alex Oliszewski.
Software Screen Shots
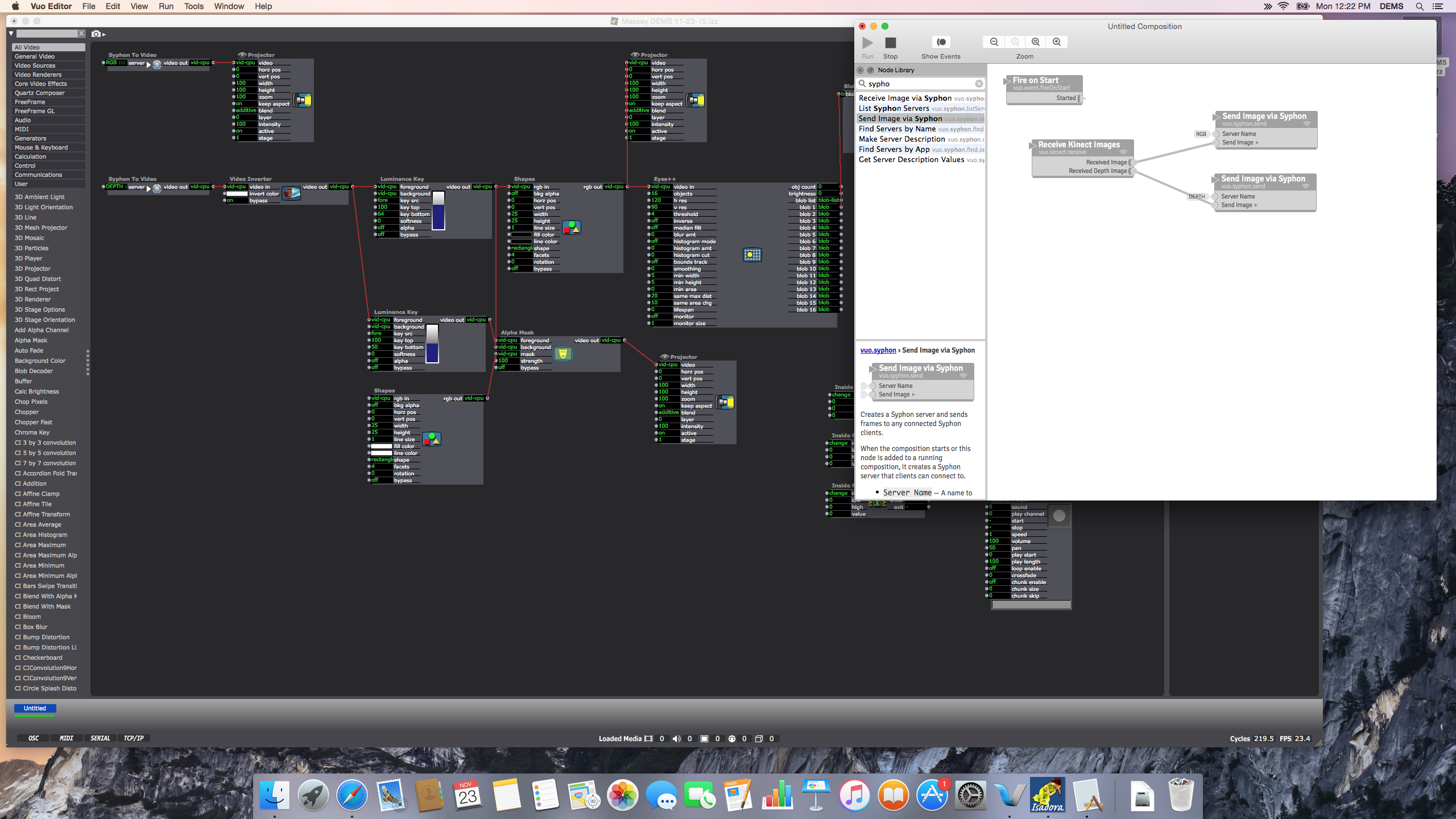
Vuo (Demo) Software connecting the Kinect through Syphon so that Isadora may intake the Kinect data through a Syphon actor:
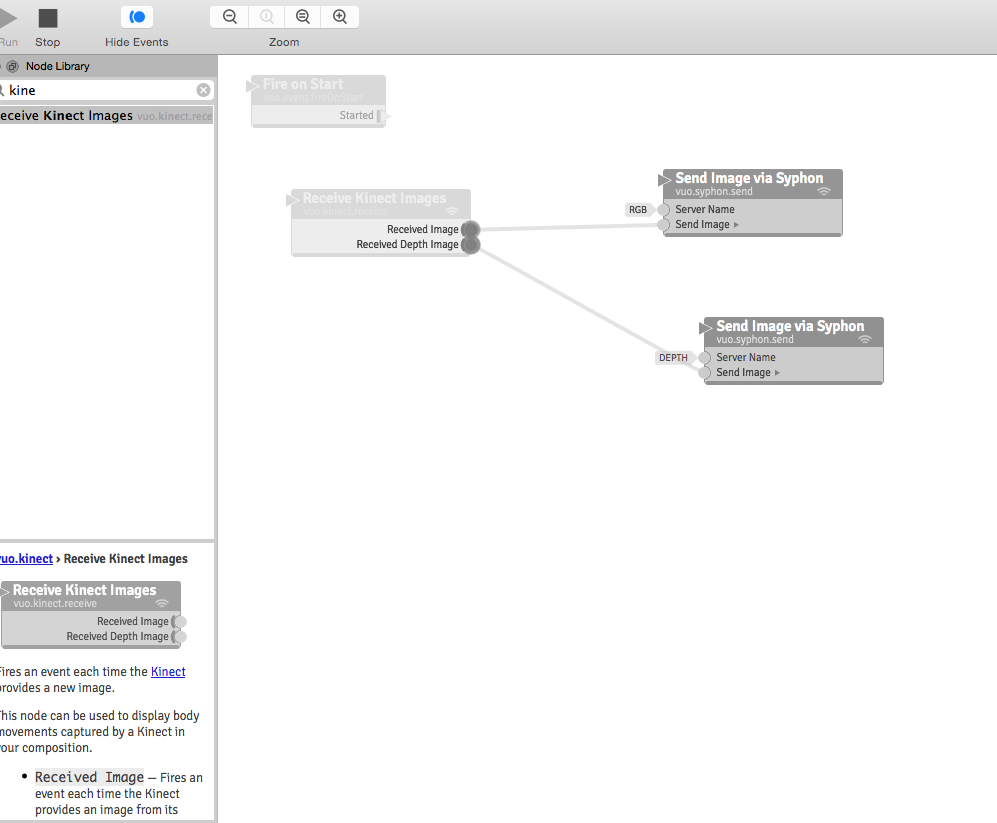
Partial shot of the Isadora patch:
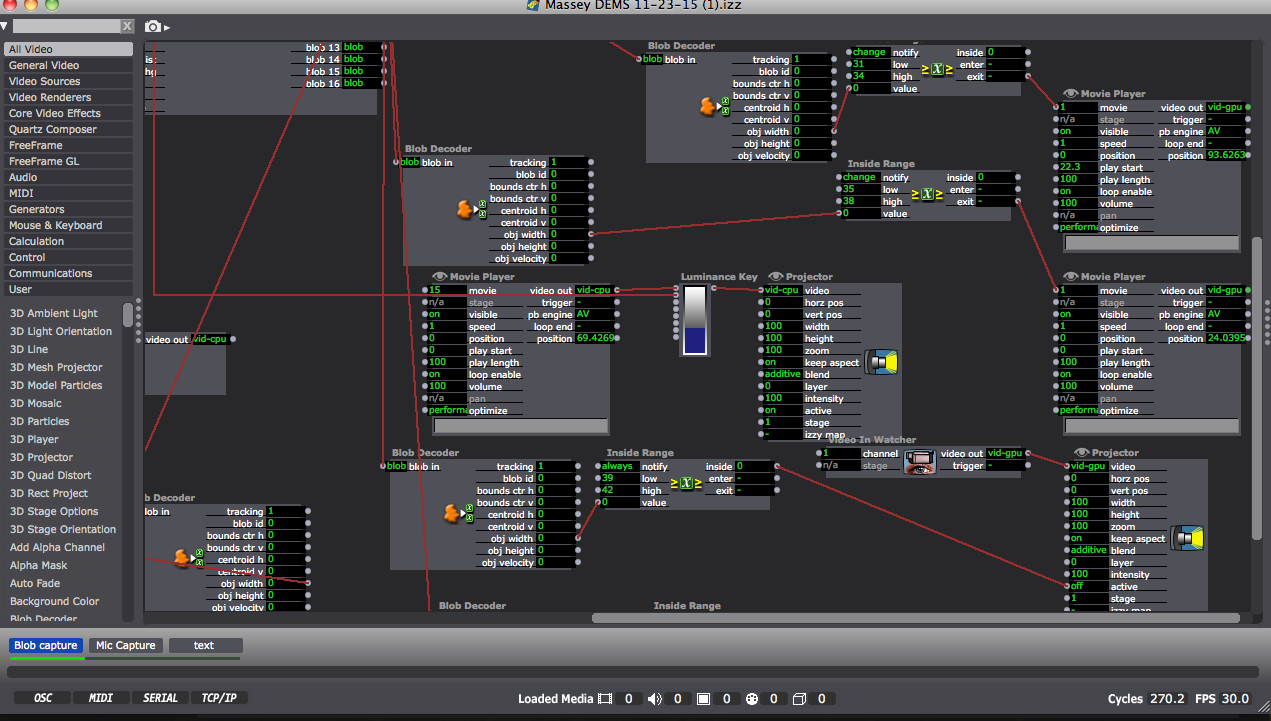
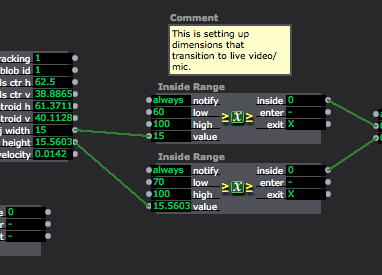
Close up of “blob” data or object dimensions coming through on the left, mediated through the Inside range actors as a way of triggering the Audio scene only when the blobs (participants) reach a certain size by joining their bodies:
Moo00oo
Posted: November 30, 2015 Filed under: Anna Brown Massey, Final Project Leave a comment »Present: Today was a day where the Vuo and Isadora patches communicated with the Kinect line-in. Alex suggested it would be helpful to record live movement in the space as a way of later manipulating the settings, but after a solid 30 minutes of turning luminescence up and down and trying to eliminate the noise of the floor’s center reflection, we made a time-based decision that the amount of time I hoped to save by having a recording off of which I could work outside of the Motion Lab would be less than the amount of time it would take to establish a workable video. I moved on.
Oded kindly spiked the floor to demarcate the space which the (center ceiling) Kinect captures. This space turns out to be oblong: deeper upstage than wider right to left. The depth data of “blobs” (“objects or people in space – whatever is present) is taken in through Isadora (first via Vuo as a way of mediating Syphon). I had Alex/Oded in space walk around so that I could examine how Isadora measures their height and width, and enlisted an Inside Range actor to set the output so that whenever the width data rises above a certain number, it triggers … a mooing sound.
Which means: when people are moving within the demarcated space, if/when they touch each other, a “Mooo” erupts. It turns out it’s pretty funny. This also happens when people spread their arms wide in the space, as my data output allows for that size.
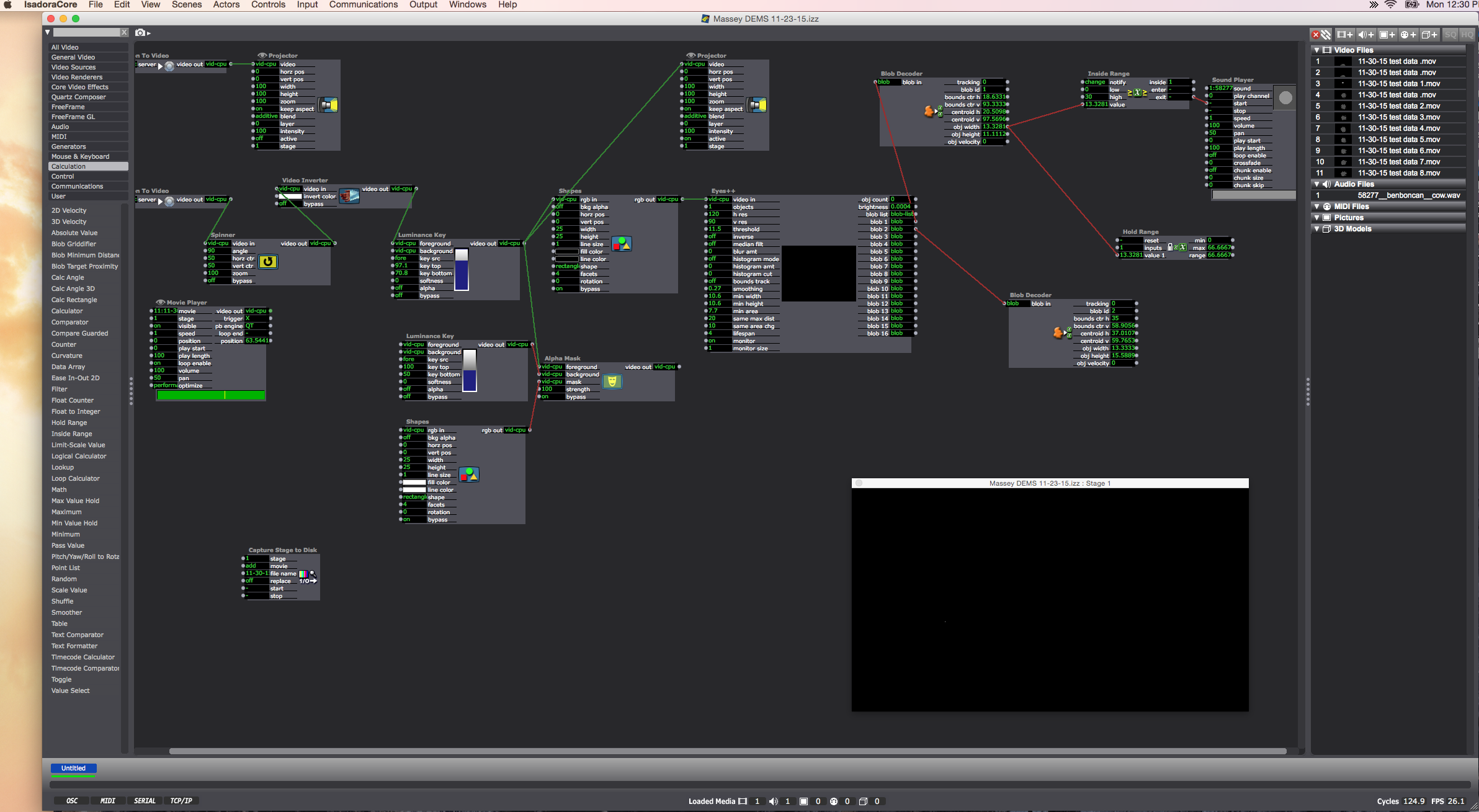
Future:
Designing the initial user-experience responsive to the data output I can now control: how to form the audience entrance into the space, and to create a projected film that guides them to – do partner dancing? A barn-cowyboy theme? In other words, how do I get my participants to touch, and to separate while staying within the dimensions of the Kinect sensor, and they touch by connecting right-to-left in the space (rather than aligning themselves upstage-downstage). Integrating the sound output of a cow lowing, and having a narrow and long space is getting me thinking on line dancing …
Blocked at every turn
Posted: November 30, 2015 Filed under: Anna Brown Massey, Final Project Leave a comment »- Renamed the server in Vuo (to “depth anna”) and noted that the Syphon to Video actor in isadora allowed that option to come up.
- Connected the Kinect with which Lexi was successfully working to my computer, and connected my Kinect line to hers. Both worked.
This was one of those days where all I started to feel I was running out of options:
UPDATE 11-30-15: Alex returned to run the patches from the MOLA preceding our before-class meeting. He had “good news and bad news:” both worked. We’re going to review these later this week to see where my troubleshooting could have brought me final success.
Dominoes
Posted: November 19, 2015 Filed under: Anna Brown Massey, Final Project Leave a comment »
I am facing the design question of how to indicate to the audience the “rules” of “using” the “design” i.e. how to set up a system of experiencing the media, i.e. how to get them to do what I want them to do, i.e. how to create a setting in which my audience makes independent discoveries. Because I am interested in my audience creating audio as an input that generates an “interesting” (okay okay, I’m done with the quotation marks starting… “now”) experience, I jotted down a brainstorm of methods of getting them to make sounds and to touch preceding my work this week.
We use “triggers” in our Isadora actors, which is a useful term for considering the audience: how do I trigger to the audience to do a certain action that consequently triggers my camera vision or audio capture to receive that information and trigger an output that thus triggers within the audience a certain response?
Voice “from above”
- instructions
- greeting
- hello
- follow along – movement karoaoke
- video of movement
- → what trigger?
- learn a popular movement dance?
- dougie, electric slide, salsa
- markings on floor?
- dougie, electric slide, salsa
- video of movement
- follow along touch someone in the room
- switch to kinect – Lexi’s patch as basis to build if kinesphere is bigger then creates output
- what?
- every time people touch for sustained length is creates
- audio? crash?
- lights?
- how does this affect how people touch each other
- what needs to happen before they touch each other so that they do it
- switch to kinect – Lexi’s patch as basis to build if kinesphere is bigger then creates output
- follow along karaoke
- sing without the background sound
- Maybe with just the lead-in bars they will start singing even without music behind
- sing without the background sound
The Present
Posted: November 9, 2015 Filed under: Anna Brown Massey, Final Project Leave a comment »The Past
I am currently designing an audio-video environment in which Isadora reads the audio and harnesses the dynamics (amplification level) data, and converts those numbers into methods of shaping the live video output, which in its next iteration may be mediated through a Kinect sensor and separate Isadora patch.
My first task was to create a video effect out of the audio. I connected the Sound Level Watcher to the Zoom data on the Projector actor, and later added a Smoother in between in order to smooth the staccato shifts in zoom on the video. (Initial ideation is here.)
Once I had established my interest in the experience of zoom tied to amplitude, I enlisted the Inside Range actor to create a setting in which past a certain amplitude, the Sound Level Watcher would trigger the Dots actor. In other words, whenever the volume of sound coming into the mic hits a certain point and above, the actors trigger a effect on the live video projection in which the screen disperses into dots. I selected the Dots actor not because I was confident that it would create a magically terrific effect, but because it was a familiar actor with which I could practice manipulating the volume data. I added the Shimmer actor to this effect, still playing with the data range that would trigger these actors only above a certain point of volume.
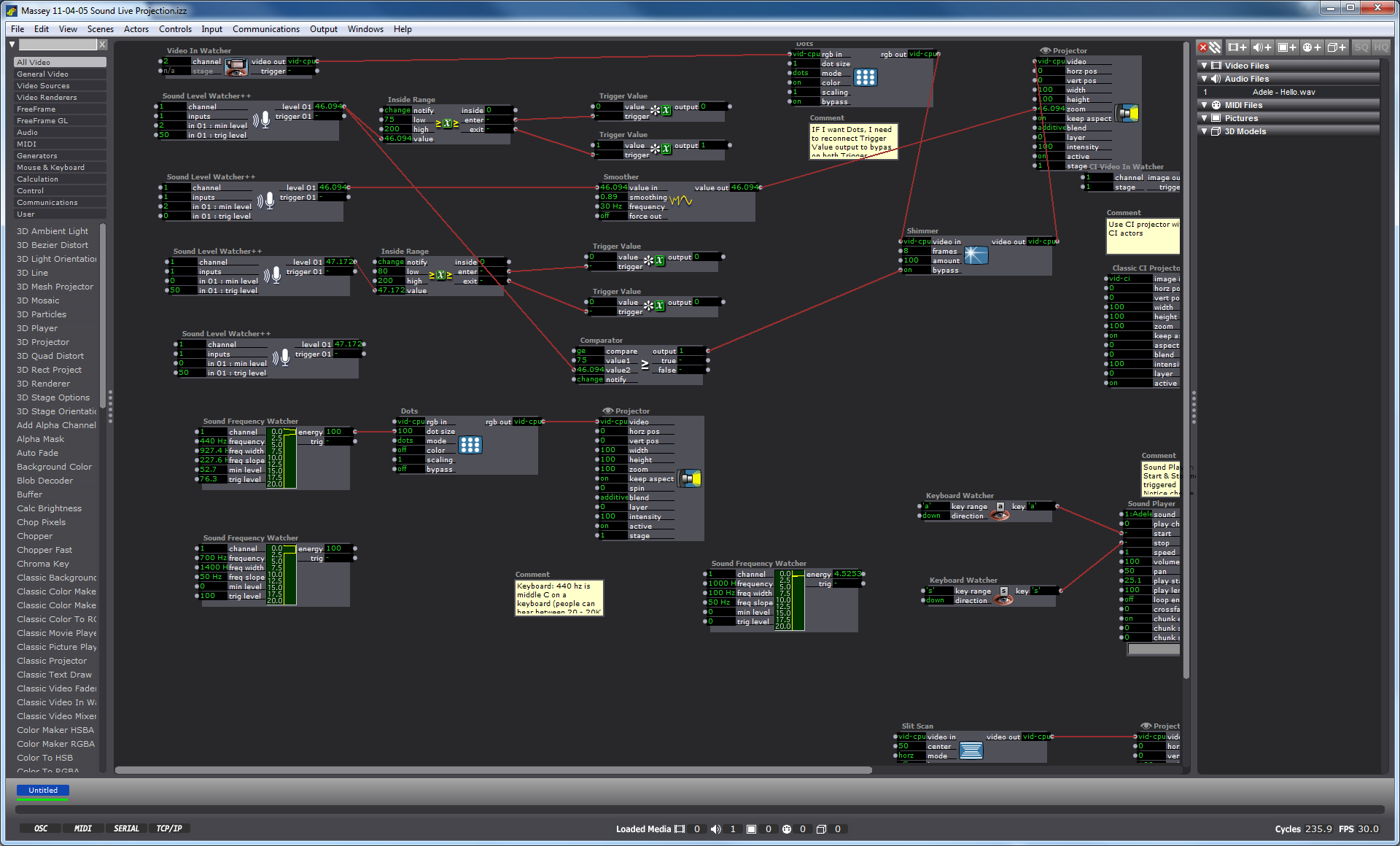
The Future
User-design Vision:
Through this process my vision has been to make a system adaptable to multiple participants of a range between 2 and 30 who can all be simultaneously engaged by the experience and possibly having different roles by their own self-selection. As with my concert choreography, I am strategizing methods of introducing the experience of “discovery.” I’d like this one to feel, to me, to be delightful. With a mic available in the room, I am currently playing with the idea of having a scrolling karaoke projection with lyrics to a well-known song. My vision includes a plan to plan on how to “invite” an audience to sing and have them discover that the corresponding projection is in causation relationship to the audio.
Sound Frequency:
Next steps, as seen at the bottom of the screenshot (and on the righthand side some actors I have laid aside for possible future use), is to start using the Sound Frequency actor as a means of taking in data about pitch (frequency) as a means of affecting video output. To do so I will need to provide an audio file in a variety of ranges as a source to experiment to observe how data shifts at different human voice registers. Then I will take the frequency data range and match that up, through an inside actor, to connect to a video output.
Kinect Collaboration:
I am also considering collaborating with my colleague Josh Poston’s project which currently uses the Kinect with projection as a replacement “live video projection,” that I am currently using, and instead to affect a motion-sensing movement on a rear-projected screen. As I consider joining our projects and expand its dimensions (so to speak-oh puns!), I need to start narrowing on the user-design components. In other words, where does the mic(s) live, where the screen, how many people is this meant for, where will they be, will participants have different roles, what is the
PP3 Ideation, Prototype, and other bad poetry
Posted: October 25, 2015 Filed under: Anna Brown Massey, Final Project, Pressure Project 3 Leave a comment »GOALS:
- Interactive mediated space in the Motion Lab in which the audience creates performance.
- Interactivity is both with media and with fellow participants.
- Delight through attention, a sense of an invitation to play, platform that produces friendly play.
- Documentation through film, recording of the live feed, saving of software patches.
- Design requirements: can be scaleable for an audience of unexpected number, possibly entering at different times.
CONTENT:
Current ideas as of 10/25/15. Open to progressive discovery:
- A responsive sound system affecting live projection.
- Motion tracking and responsive projection as interactive
- How do sound + live projection and motion tracking + live projection intersect?
- Brainstorm of options: musical instruments in space; how do people affect each other; how can that be aggressive or friendly or something else; what can be unexpected for the director; could I find/use “FAO Schwartz” floor piano; do people like seeing other people or just themselves, how to take in data for sound that is not only decibel level but also pitch, timbre, rhythm; what might Susan Chess have to offer regarding sound, Alan Price, Matt Lewis.
RESOURCES
- 6+ Videocameras projecting live feed
- 3 projectors
- CV top-down camera
- Mutiple standing mics
- Software: Isadora, possibly DMX, Max MSP
VALUES i.e. experiences I would like my users (“audience” / “interactors” / “participants”) to have:
- uncertainty –> play –> discovery –> more discovery
- with constant engagement
Drawing from Forlizzi and Battarbee, this work will proceed by including attention to intersecting levels of fluent, cognitive, and expressive experience. A theater audience will be accustomed to a come-in-and-sit-down-in-the-dark-and-watch-the-thing experience, and a subversion of that plan will require attention to how to harness their fluent habits, e.g. audiences sit in the chairs that are thisclose to the work booth but if the chairs are this far then those must be allotted for the performance which the audience doensn’t want to disrupt. Which begs: how does an entering audience proceed into a theater space with an absence of chairs. Where are mics(/playthings!) placed under what light and sound “direction” that tells them where to go/what to do. A few posts ago in examining Forlizzi and Battarbee I posed this question, and it applies again here:
What methods will empower the audience to form an active relationship with the present media and with fellow theater citizens?
LAB: DAY 1
As I worked in the Motion Lab Friday 10/23 I discovered an unplanned audience: my fellow classmates. Seemingly busy with their own patches and software challenges, once they looked over and determined that sound level was data I had told Isadora to read and spit into affecting a live zoom of myself via the facetime camera the mac, I found they were, over the course of an hour frequently “messing” with my data in order to affect my projection. (I had set the incoming data of decibel level to alter the “zoom” level on my live projection.) They were loud, soft, laughing aggressively seeing the lowest threshold at which they could still affect my zoom output.
SO, discovery that decibel level affects the live projection of a fellow user seems, through this unexpected prototype due to the presence of my co-working colleagues, to offer an opportunity to find that SOUND AFFECTING SOMEONE ELSE’S PROJECTION ENGAGES ATTENTION OF USERS ALSO ENGAGED IN OTHER TASKS. okay, good. Moving forward …
Guinea Pigs
Posted: October 14, 2015 Filed under: Anna Brown Massey, Pressure Project 2 Leave a comment »Building an Isadora patch for this past project expanded my understanding of methods of enlisting CV (computer vision) to sense a light source (object) and create a projection responsive to the coordinates of that light source.
We (our sextet) selected the top down camera in the Motion Lab as the visual data our “Video In Watcher” would accept. As I considered the our light source, a robotic ball called the Sphero, manipulateable in movement via a phone application, I was struck by our shift from enlisting a dancer to move through our designed grid to employing an object. This illuminated white ball was served us not only because we were no longer dependent on a colleague to be present just to walk around for us, but also because its projected light and discreet size rendered our intake of data an easier project. We enlisted the “Difference” actor as a method of discerning light differences in space, which is a nifty way of distinguishing between “blobs.” Through this means, we could tell Isadora to recognize changes in light aka changes in the location of the Sphero, which gave us data about where the Sphero was so that our patches could respond to it.
My colleague Alexandra Stillianos wrote a succinct explanation for this method, explaining “Only when both the X and Y positions of the Sphero light source were toggled (switched) on, would the scene trigger, and my video would play. In other words, if you were in my row OR column, my video would NOT play. Only in my box (both row AND column) would the camera sense the light source and turn on, and when leaving the box and abandoning that criteria it would turn off. Each person in the class was responsible for a design/scene to activate in their respective space.”
The goal was to use CV (computer vision) to sense a light source (used by identifying the Sphero’s X/Y position in the space) to trigger different interactive scenes in the performance space.
Considering this newly inanimate object as a source, I discovered the “Text Draw” actor, and chose “You are alive” as the text to appear projected when the object moved into the x-y grid space indicated through our initial measurements. (Yes, I found this funny.) My “Listener” actor intercepted the channels “1” and “2” which we had our set-up in our CV frame to “Broadcast” the incoming light data, to which I applied the “Inside range” actor as a way of beginning to inform Isadora which data would trigger my words to appear. I did a quick youtube search of “slow motion,” and found a creepy guinea pig video that because of its single shot and stationary subjects, appeared to be possibly smooth fodder for looping. I layered two of these videos on a slight delay to give them a ghostly appearance, then added an overlay of red via the shapes actor.
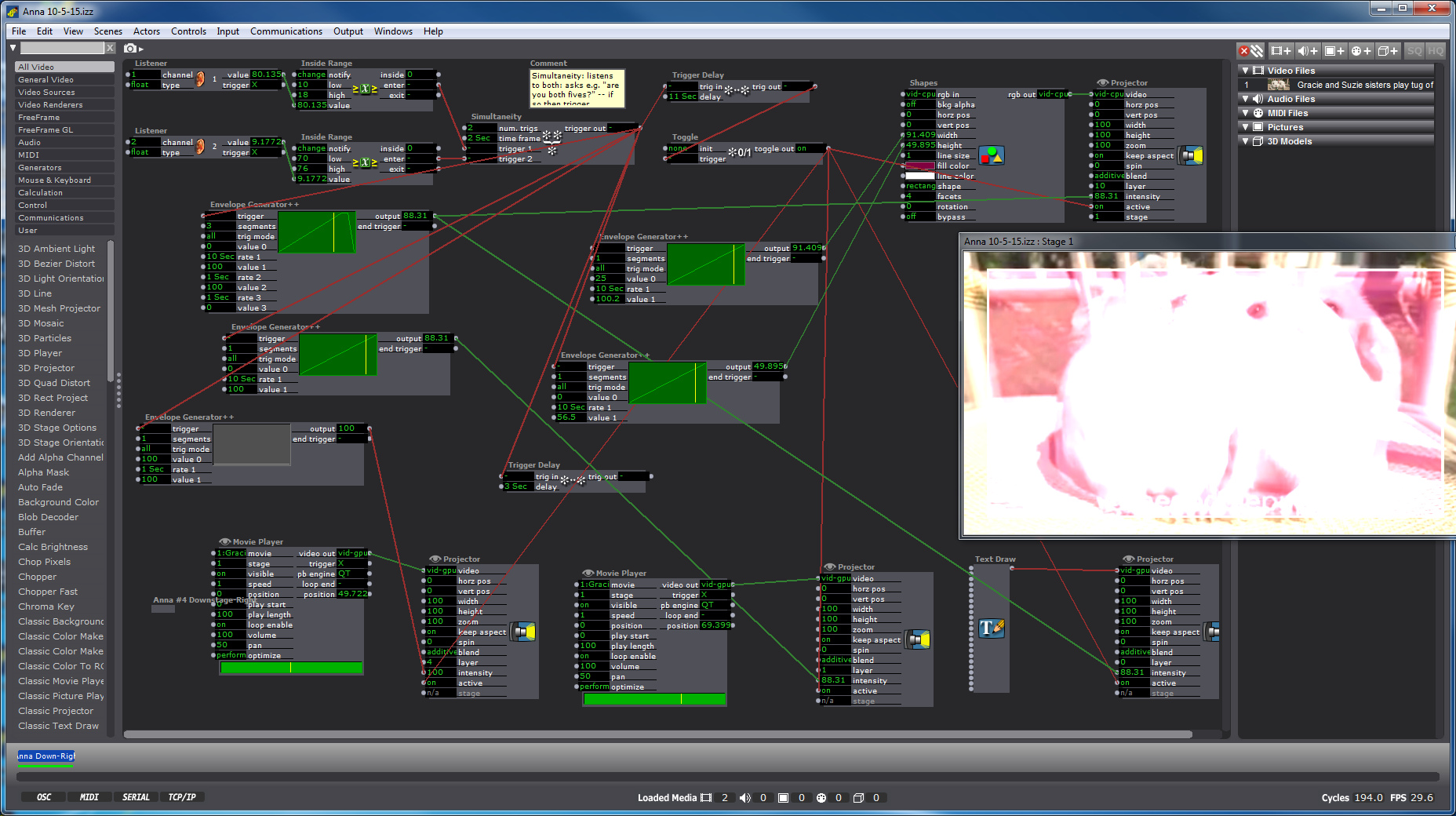
As we imported our video/sound/image files to accompany our Isadora patches into the main frame, we discovered that our patches were being triggered, but were failing to end once the object had departed our specific x-y coordinates as demarcated for ourselves on the floor, but more importantly as indicated by our “Inside Range” actors. We realized that our initial measurements needed to be refined more precisely, and with that shift, my own actor was working successfully, but we were still faced with difficulty in changing the coordinates on my colleague’s actor as he had multiple user actors embedded in user actors that continued to run parts of his patch independently. The possibility of enlisting a “Shapes” actor measured to create a projection of all black was considered, but the all-consuming limitation on time kept us from proceeding further. My own patch was limited by the absence of a “Comparator” as a means of refining the coordinates so that they might toggle on and off.
Repetition & Repetition
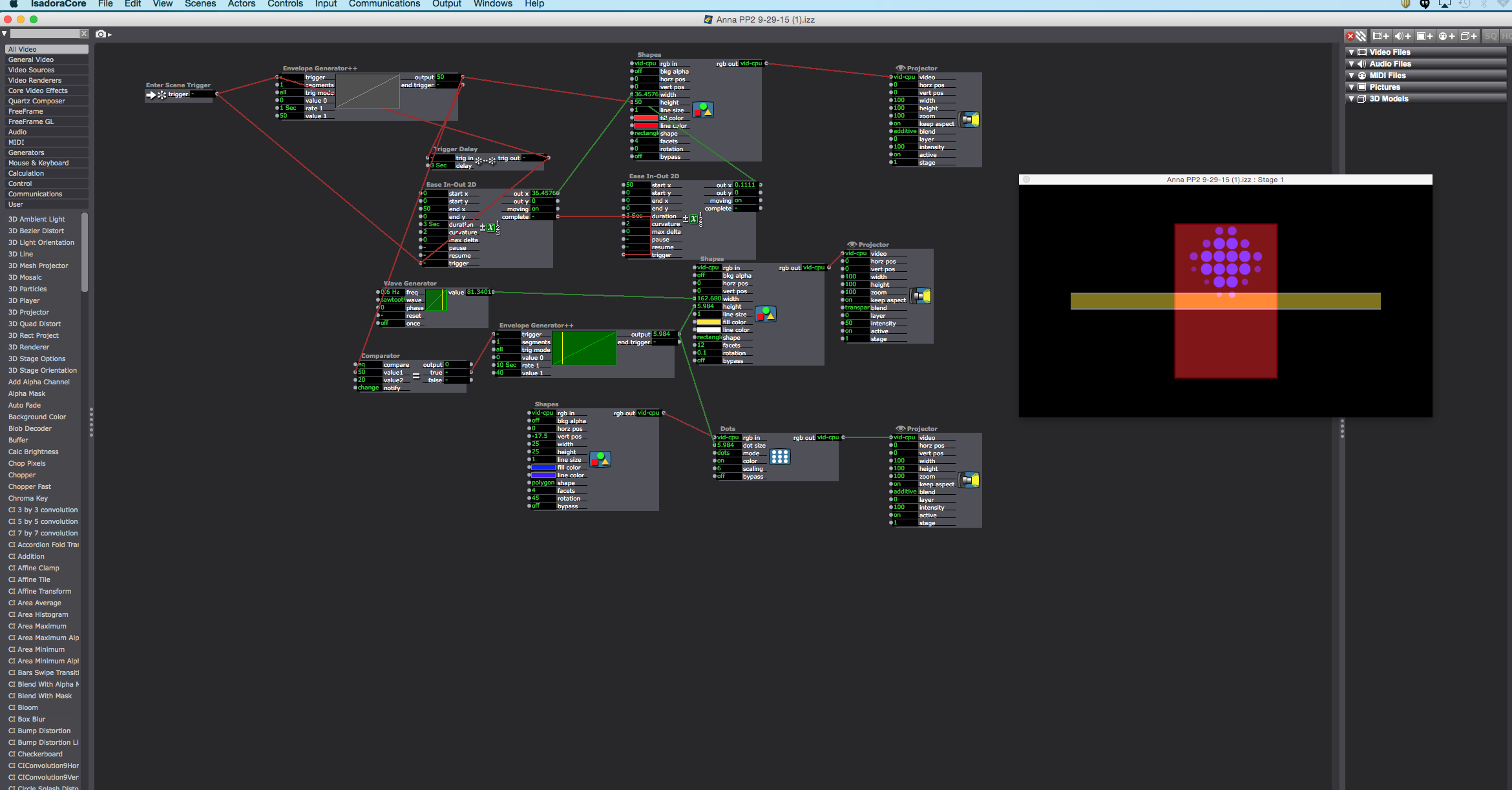
Posted: September 30, 2015 Filed under: Anna Brown Massey, Pressure Project 2 Leave a comment »I made several pressure projects because I realized that in order to learn to build a system independently, I needed to start over multiple times. Each beginning was formed with support. Once I had created an initial course of shapes altered through actors to land in a projected stage, and I could progress through adding shapes and additional actors, I found I could look backwards to my initial connections in order to firmly establish which trigger in/outs were correct. I need to know I could manifest them again. So I started over. Replication was teaching me, but repetition was going to teach me better. And so, I’ve arrived at a rather mediocre little looping film of shapes with timed motion and transparencies as its the fourth miniature project of building similar projections. No doubt this restarting choice, with multiple short films was certainly influenced by a few other it’s-real-life factors: a flu, a power outage during my last project, and a subsequent broken computer in the last hours of plans to submit. (A note of gratitude to the OSU media lab in which I am now writing this post.)
The familiar challenge of building a looping project that sustains attention is not lost on this dance and filmmaker. Repetition tends to breed the encouragement to “look” elsewhere, e.g. that dancer has been doing the same forward and back run for a minute, he’s likely to continue, now I am free to examine other elements of the experience. When there are no other elements, attention may fade–or build with the sensation of subtle change or detail. I found with the initial shapes moving through the space, I engaged with an aesthetic draw; even if it repeats and is “boring,” if it’s “attractive,” it’s engaging. Or is it: if it’s engaging it’s attractive? In this last patch, there are three main shapes. How to make three shapes be just the most fascinating thing; this frankly, is not something I have yet arrived at, but with this project I am beginning to find the possibilities that I can actually do. Right now the bluntness of my abilities is blunting not my imagination but my ability to manifest ideas into an actual projection. (I’ve got some grand ideas for a new piano sonata, but I’ve got to learn to play the piano first, etc., etc.) Discovering the Dots actor and extending its own timing while changing its rotation felt like I was able to bring in an element that changed enough to sustain a slight furthering of a viewer’s attention. I had originally played with the Kaleidoscope Actor (misspelled in Isadora), imagining a wealth of change, but discovered it was not applying as generative change as I had expected. I applied Dots instead, recalling a colleague’s mentioning of their current favored actor for the project. I altered the color in addition to the rotation, played with its timing, and set it going in hopes of having a minute experience of moving shapes to keep you watching.
Posted: September 14, 2015 Filed under: Anna Brown Massey, Reading Responses Leave a comment »
Some notes
RSVP Cycles – Lawrence Halprin
Scores
- as symbolizations of process e.g. musical, grocery list, calendar, this book
- as method of making process visible
- can communicate processes over space-time
- Hope for socres as way of designing large-scale environments
- Must allow for feedback
- as potential communication device
Environment + dance-theater
- non-static
- process-oriented (not result-oriented)
- values present, but not demonstrable
Resources
Scores
Valueaction
Performance
Order can be any. e.g PRSV
Cycle works at two levels: self, group
– meant to be free–making processes visible
Danger: becoming goal-oriented… scores are non-utopian; they’re idealistic, hope-oriented
Score: system of symbols to convey/guide/control interactions between elements: space, time, rhythm, and their sequences, people and activities, and the combinations that result
An Arts Sciences, Engineering Educational Research Initiative for Experiential Media by Rikakis, Spanias, Sundaram, He (2006)
Summary: training approach f/ integrating computation & media in physical human experience
- driven by research problems
- based on interdisciplinary network
- research and application
- transdisciplinary training
Experiential Media: systems that integrate computation and digital media in physical media experience
Three trends in computation:
- novel embedded interfaces e.g. gesture, movement, voice, sketches, etc
- human e.g. computing communication at level of meaning (rather than level of information)
- participational knowledge creation and content e.g. generation frameworks
Research model 5 areas
- Sensing: human word & physical activity
- Perception and modeling
- Feedback
- Experiential construction
- Learning and knowledge
Expertise needed:
- sensing: engineers
- media communication & experiential construction: artists
- perception, cognition, learning: psychology & education experts
Arizona State University has Arts, Media, Engineering (AME) program
Application of this training-research: health, education, social communication, everyday living, culture, arts
Need new folks trained in this
The Work of Art in the Age of Digital Reproduction by Douglas Davis (1991-5)
No longer clear conceptual distinction between original and reproduction – both states are “fictions”
Not “virtual” — actually, virtual is “RR”: Realer Reality
The World’s First Collaborative Sentence ….
Digital reproduction is without degradation: always same/perfect
Empower imagination, not reason –> new tools e.g. printed word invented led hundreds of years later to Ulysses
Reader becomes author on internet –> information is decentralized
We can walk, think, feel virtual world same as human-made world
Deconstruction itself has its own value
When live performers leave the stage and there’s a “live feed” of them backstage, we are unsure whether it’s taped for live e.g. Blue Man Group
Status of first person is still valued
“poststructuralism” “postmodernism” “post-avant-garde” “appropriation”…
* aura resides “not in the thing itself but in the originality of the moment we see, hear, read, repeat, and revise” (386)
There is only software (Manovich)
Posted: September 7, 2015 Filed under: Anna Brown Massey Leave a comment »Okay, okay, jeez. I get it. THERE IS ONLY SOFTWARE
“There is no such thing as digital media. There is only software–as applied to media data (or ‘content’).
“Digital media” and “new media” are not enough
Digital representation makes computers possible.
Software determines what we can do with them.